
Given a set of images, which contain several persons, the objective of "human co-detection" problem includes (1) detecting human in the image set and (2) labeling them into groups by their identities.
Jianping Shi Renjie Liao Jiaya Jia
The Chinese Univeristy of Hong Kong
|
Given a set of images, which contain several persons, the objective of "human co-detection" problem includes (1) detecting human in the image set and (2) labeling them into groups by their identities. |
Downloads
 |
"CoDeL: An Human Co-detection and Labeling Framework" Jianping Shi, Renjie Liao, Jiaya Jia IEEE International Conference on Computer Vision (ICCV), 2013 |
Abstract
We propose a co-detection and labeling (CoDeL) framework to identify persons that contain self-consistent appearance in multiple images. Our CoDeL model builds upon the deformable part-based model to detect human hypotheses and exploits cross-image correspondence via a matching classifier. Relying on a Gaussian process, this matching classifier models the similarity of two hypotheses and efficiently captures the relative importance contributed by various visual features, reducing the adverse effect of scattered occlusion. Further, the detector and matching classifier together make our model fit into a semi-supervised co-training framework, which can get enhanced results with a small amount of labeled training data. Our CoDeL model achieves decent performance on existing and new benchmark datasets.
Framework
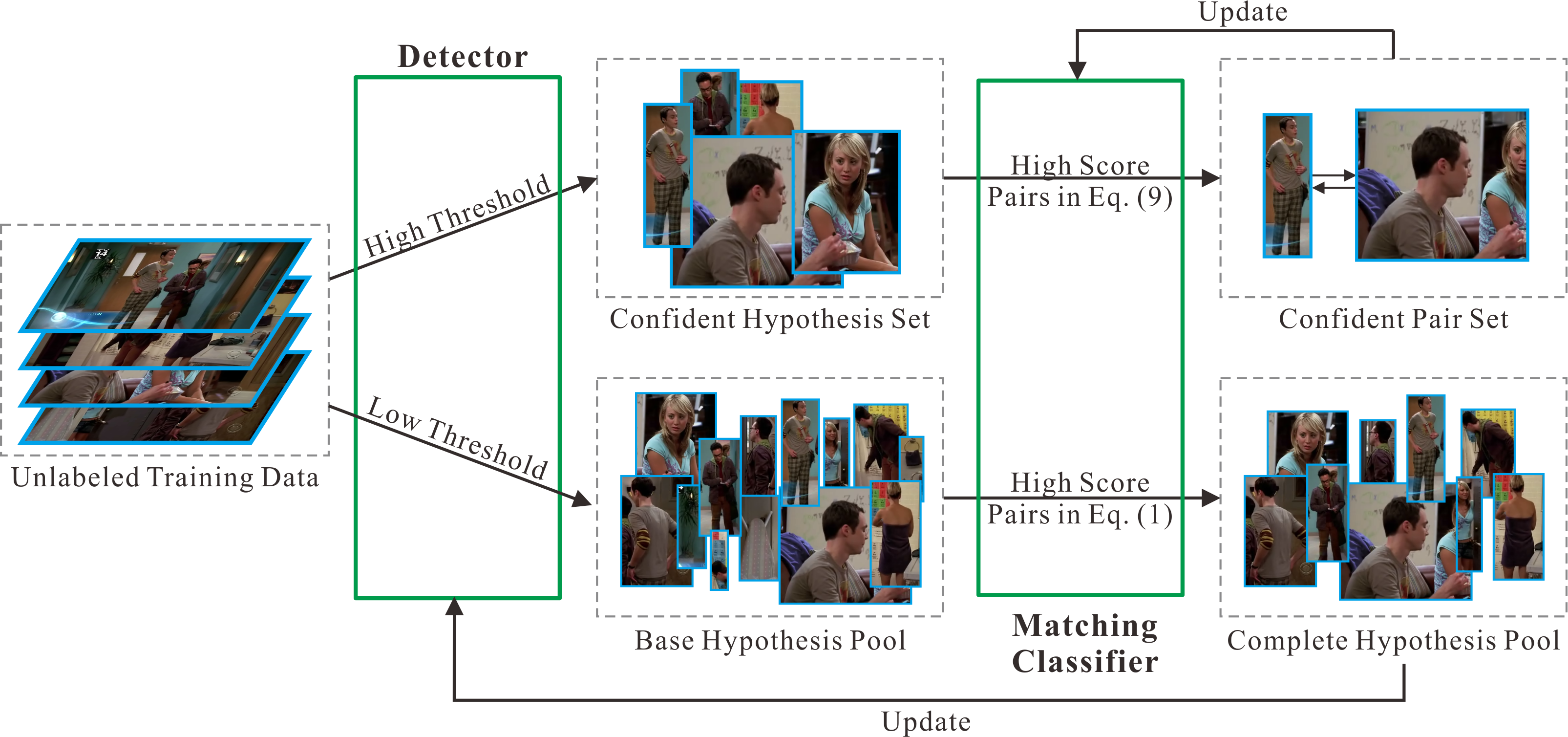
An overview of our CoDeL framework. Our CoDeL follows a co-training scheme to consider insufficient labeled data. It trains two classifiers, including detection and matching, based on two feature sets, which are conditionally independent given the class labels, to help improve each other by adding weak positive samples to the training set. The detected region gives a clear indication on which part of the image is used for matching. Meanwhile, the matching process among different images can help retrieve missing data as well as rejecting false alarms for the detector.
Take Home Message
1. The detection and matching classifiers together make our model fit a semi-supervised co-training framework, which achieves decent results with a small amount of initial labeled training data.
2. The cross-image correspondence in color and texture features can improve the detection results, and provide a natural extension for human identity grouping.
Last update: October 4, 2013